- TOP
- レポート・ライブラリ
- 対話型AIの可能性を急速に高めるChatGPT - GPTの企業利用に向けた考察 -
ITR Review
- コンテンツ番号:
- R-223052
- 発刊日:
- 2023年5月1日
対話型AIの可能性を急速に高めるChatGPT
GPTの企業利用に向けた考察
- 著者名:
-
三浦 竜樹

OpenAI社が公開した人工知能チャットボットであるChatGPT(Generative Pre-trained Transformer)は、AIやITに従事する人だけでなく、企業の各種業務部門のユーザーからも注目を集めている。そして、ChatGPTの発表以降、ベースである大規模言語モデルを取り巻く環境は急速な進展を見せている。本稿ではChatGPTについて解説するとともに、企業における活用について考察する。
ChatGPTとは
ChatGPTは、OpenAI社が2022年11月に公開したジェネレーティブAI(生成AI)であり、大規模言語モデルであるGPT-3.5を基に対話に適したモデル(チャットボット)へと、RLHF(Reinforcement Learning with Human Feedback:人間のフィードバックを用いた強化学習)と呼ばれる手法によって微調整したものである。GPT-3.5は自然言語処理モデルであり、人間が書いたかのような自然なテキストを生成することから、現在最も注目されている。これまで大規模言語モデルとしては、Google社が提供するBERTが知られている。BERTは、文章を読む(理解する)ことに注力した言語モデルであり、チャットボットにおいて自然文の質問を理解し、回答を見つけることは得意であったが、自然なテキストでの回答ではなかった。これに対してChatGPTは、GPT-3.5の特徴である、自然なテキストの回答や要約された回答を返せる側面が特に注目されている。その根幹には、大規模なテキストデータを事前に学習し、わずかなタスクを与えるだけで、文章生成/校正、翻訳、音声認識、要約、感情分析などの言語処理タスクを行える大規模言語モデルの存在がある。
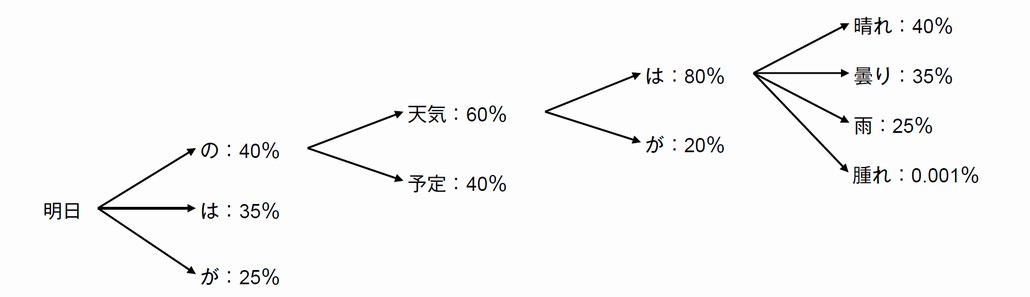
言語モデルの基本は、自然言語処理において単語の出現確率を学習し、その確率を基に次に出現する単語を予測することである。図1は、「明日」という単語から、これに続く単語を確率から予測する言語モデルの簡単な例である。それぞれ確率の高い単語を選択していくことで、「明日の天気は晴れ」という予測精度の高い文章を生成する。GPT-3では、約45TBの大規模なテキストデータのコーパス(言語学において統計的な分析や研究を行う目的で集められ構築された、言語テキストの集合体)を約1,750億個のパラメータを使用して学習しているため、高い精度での予測が可能となっており、OpenAI社が2023年3月14日に発表したGPT-4では、パラメータ数などは非公開であるが、さらに精度が高まったとしている。その例として、米国司法試験の模擬試験に対する成績はGPT-3では下位10%の成績で合格したのに対し、GPT-4では上位10%で合格した、と同社は述べている。
図1.言語モデルのイメージ
ITR 著作物の引用について
ITRでは著作物の利用に関してガイドラインを設けています。 ITRの著作物を「社外利用」される場合は、一部のコンテンツを除き、事前にITRの利用許諾が必要となります。 コンテンツごとに利用条件や出典の記載方法が異なりますので、詳細および申請については『ITR著作物の引用ポリシー』をご確認ください。